

Epochs in machine learning can be confusing for newcomers.
This guide will break down epochs and explain what they are, how they work, and why they’re important.
We’ll also dive deep into Epochs’ relationship with Batch size and iterations.
Deep learning is a complex subject, but by understanding epochs, you’re on your way to mastering it!

What is an Epoch in Machine Learning?
When we train a neural network on our training dataset, we perform forward and back propagation using gradient descent to update the weights.
To do this, forward and back propagation requires inputting the data into the neural network.
There are three options to do this:
1.) One by One
2.) Mini Batches
3.) Entire Batch
Feeding your neural network data one by one will update the weights each time using gradient descent.
If you feed your neural network data with mini-batches, after every mini-batch, it’ll update the weights using gradient descent.
Batch Size is equal to N/2 (Mini Batch)
And finally, if you feed your neural network your entire dataset, it’ll update the weights each time using gradient descent.
However, no matter how you feed the data to your neural network, once it’s seen the entire dataset, this is one Epoch.

Using one by one will take N updates (where N is the # of rows in your dataset) for one Epoch.
In contrast, using the entire dataset will only take one update for one Epoch.
Why do we use more than one Epoch?
Since one Epoch is when our machine learning algorithm has seen our entire dataset one time, more data is needed for our algorithm to learn the hidden trends within our dataset.
This is why we use more than one Epoch to provide enough data to train our algorithm.
How to Choose The Right Number of Epochs
There’s no magic number when choosing the correct number of epochs for training your machine-learning algorithm.
You’ll generally set a number high enough that your algorithm can learn your dataset but not too high where you’re wasting resources and overfitting.
The best way to find the perfect balance is through trial and error.
Start with a relatively high number of epochs and gradually decrease until you find the sweet spot.
It might take a little time, but getting the best results is worth it.

What Is the Difference Between Epoch and Batch In Machine Learning?
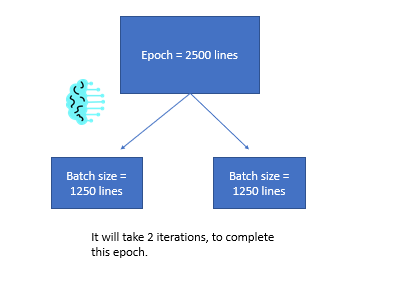
An epoch is running through the entire dataset once, and batch size is just how many “chunks” we do it in.
If we have a dataset of 1000 points and a batch size of 10, we’re going to train our model on 10 points at a time, update our weights 10 points at a time, and do that 100 times.
That’s one Epoch.
If we want to run more epochs, we keep going until we hit our stopping criterion.
Pretty simple, right?
We do this because we don’t try to process too much data at once and overload our RAM. If you’re only processing 10 points at a time, you’ll be safe from memory overload.
There are other benefits, too – like stopping training if the validation loss isn’t improving after a certain number of epochs or if the training loss starts increasing (which would mean you’re overfitting).
Do Different Frameworks Have Different Meaning For Epoch?
Whether you’re using TensorFlow, PyTorch, or whatever new deep learning framework comes out in the future – an epoch is one run through the entire dataset.
The meaning of Epoch has eclipsed module usage and is taught as a fundamental part of deep learning.
Whenever someone references an epoch, they’re talking about your dataset, seeing the entire training set.

Does an Epoch Exist Outside of Machine Learning?
While the idea behind Epoch does exist outside of machine learning, you won’t hear it called “epoch.”
For example, if you’re working as a data scientist and are building a visualization for a chart – you’d use the entire dataset.
This would be an “epoch,” but your boss would never reference it that way, as it’s not standard jargon outside machine learning.
So an epoch does exist outside of machine learning, but the terminology would never be used outside of machine learning (and mostly deep learning contexts).
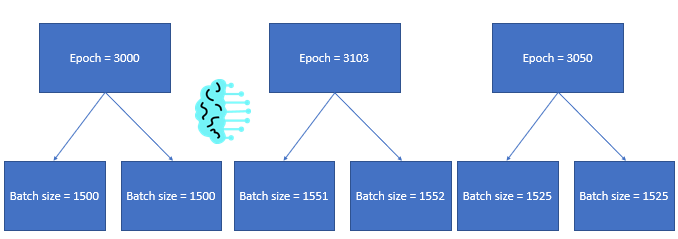
What is an iteration in machine learning?
An iteration is how many updates it takes to complete one Epoch.
In other words, it’s the number of times the model weights are updated during training.
The term comes from the Latin word iter, meaning “to go through or do again.”
Higher iterations, in my experience, improve accuracy but take longer to train because the model has to update the weights much more often.
Trade-offs between the interaction of iterations and batch size exist.
As you increase batch size, your iterations are lowered.
For example, you might want to use fewer iterations if you train a model on a small dataset, as you’ll be able to fit most of the dataset into memory.
But if you’re training a model on a large dataset, you might want to increase iterations (which would lower batch size) because it would take too long to train the model otherwise – and probably wouldn’t fit into ram.
Experimenting with different values and seeing what works best for your situation is essential.

Do Many Epochs Help Our Gradient Descent Optimization Algorithm Converge?
Increasing the number of Epochs your algorithm sees will help until a certain point. Once that point is reached, you’ll start overfitting your dataset.
As a machine learning engineer, your job is to find that sweet spot where your algorithm is seeing enough data but not so much that it’s started focusing on the noise of the training data.
A validation dataset will help track the loss and create programmatic stops if the loss starts to increase.
Other Quick Machine Learning Tutorials
At EML, we have a ton of cool data science tutorials that break things down so anyone can understand them.
Below we’ve listed a few that are similar to this guide:
- Instance-Based Learning in Machine Learning
- Verbose in Machine Learning
- Hypothesis in Machine Learning
- Noise In Machine Learning
- Inductive Bias in Machine Learning
- Types of Data For Machine Learning
- Understanding The Hypothesis In Machine Learning
- Zip Codes In Machine Learning
- Generalization In Machine Learning
- get_dummies() in Machine Learning
- X and Y in Machine Learning
- F1 Score in Machine Learning
- Bootstrapping In Machine Learning
