

We’ve all been there, cleaned up our dataset, and realized it’s incredibly noisy.
Should you get rid of the noise? Why is it even there? And what even is noise?
In this blog post, we’ll look at what noise is, why it matters in machine learning, and whether or not we want it in our systems.
I’ll even throw in some code to get you on your way!
What is Noise in Machine Learning
Noise in Machine Learning is like the static you hear on an old-fashioned TV set: unwanted data mixed in with the clean signals, making it hard to interpret and process “the good stuff.”
Noise can also adversely affect a Machine Learning model’s accuracy, hindering the algorithms from learning the authentic patterns and insights in the data, as the noise masks these.

While many focus on the more common types of noise in Machine Learning, like outliers, corrupted data points, and missing values, this noise is easy to detect and handle.
The best way to manage this type of noise is by understanding the problem context and implementing necessary preprocessing techniques like outlier/anomaly detection and other standard procedures.
The actual problem with noise arises from the randomness of the world, which is much harder to detect.
While many will tell you this noise will ruin your models, I’d argue it can sometimes enhance them.
If you handle it correctly.
Does every real-world dataset have noise in it?
All real-world datasets have noise, even if the dataset seems perfect.
While many machine learning practitioners will argue that this noise needs to be removed, I’d argue it needs to be understood first.
Do we want to remove all noise from data in Machine Learning?
You should be very careful of removing noise in machine learning models, as it’s tough to distinguish between noise in your data and nuances in a system.

For example, let’s say you’re building a system to predict if someone will signup for your SAAS product.
You have data on a bunch of unfinished and finished signup forms, seeing if people convert.
Now, you see your dataset, and the unfinished signup forms are half finished, generally not completely filled in, and sometimes need more accurate information.
The first thing many machine learning practitioners will do is throw out this incomplete data.
That makes sense, right?
It’s “bad” data and doesn’t seem to provide anything (it’s really noisy data).
Now, what if I told you that after someone creates a half-filled forum, they come back within a week and signup for the product at a 60% rate?
Well, now wait, those half-finished signup forms are no longer bad and noisy data; they’re highly predictive and will allow us much higher accuracy for a forecasting model.
This is the problem with removing noise; understanding a problem deep enough to remove all noise takes a ton of business context that I think only some of us have.
That’s okay – there are other things we can do.
How to remove all types of noise for our learning models in python
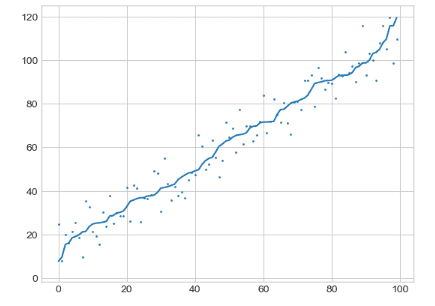
Instead of feeding your algorithm noisy data, you can use a lowess curve to create smooth points to feed.
Here is an example in python, using statsmodels.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
plt.style.use('seaborn-whitegrid')
# example of a noisy parameter
x = [val for val in range(0,100)]
y = [np.sin(val) + (np.random.normal(val) + random.randint(0,25)) for val in x]
plt.scatter(x, y, 1)We can see how noisy our data points are

import statsmodels.api as sm
z = sm.nonparametric.lowess(x, y, frac=1/3, it=3)
plt.scatter(x, y, 1)
plt.plot(x, z[:,0], 4)
plt.show()Here are our new “Z” points, which our lowess curve has smoothed!
Is it possible to label noise before modeling?
Noise can be labeled before modeling using the lowess technique shown above.
Though, this is wasted time.

You’d have much better model improvements focusing on getting a cleaner dataset or understanding the problem more deeply.
Are there ever scenarios where you want to add noise in machine learning?
Noise is constantly added to datasets.
In image detection, it’s very standard to rotate and flip images to try and trick our algorithm.
This will give us more images to model and a more general algorithm that will be much more robust in production.
Adding noise is a way of generalizing models.
What is the difference between Noise and Error In Data Science?
Noise is something that datasets have; error is something that models deal with.
Noise is before we begin modeling, and error is after.
Are Noise And Outliers The Same In Data Science?
There is an argument there, but traditionally, noise is the randomness of the world being injected into your dataset.
While outliers could be seen as noise, they’re usually signs of something else, like process failure and data collection issues.
Other Quick Machine Learning Tutorials
At EML, we have a ton of cool data science tutorials that break things down so anyone can understand them.
Below we’ve listed a few that are similar to this guide:
- Instance-Based Learning in Machine Learning
- Verbose in Machine Learning
- Hypothesis in Machine Learning
- Bootstrapping In Machine Learning
- Inductive Bias in Machine Learning
- Epoch In Machine Learning
- Understanding The Hypothesis In Machine Learning
- Zip Codes In Machine Learning
- get_dummies() in Machine Learning
- X and Y in Machine Learning
- F1 Score in Machine Learning
- Generalization In Machine Learning
