

In natural language processing, understanding the meaning (semantics) of a corpus (text) is essential. But how can computers derive meaning from text if computers can’t read? How can they find sentences with similar similarity metrics if they, again, can’t read?
Complete Semantic Similarity Between Sentences Coded in Python At Bottom
What Does Semantics Mean In Computer Science
Semantics in computer science is the mathematical reasoning behind a legal string defined by a programming language. This is the opposite of syntax, the rules governing your program. It’s easiest to think of syntax as structure and semantics as meaning.
What Is The Difference Between Syntax and Semantics
Understanding the difference between syntax and semantics is easiest to see with an example.
Here is a function that syntactically is perfect but semantically makes no sense.
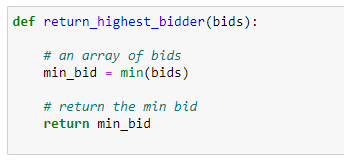
Why would you return the minimum in this context? Is the function named wrong? Is the algorithm wrong?
Here is a function that semantically makes perfect sense but syntactically is wrong.
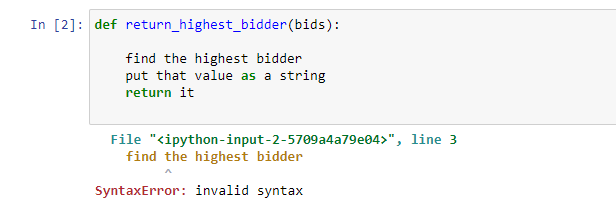
As we can see, semantics (in computer science) only cares about the actual meaning behind code.
While you can follow all of the rules of your particular programming language (python in this example), your program can make no sense or be wrong.
And contrary to the previous example, your code could make perfect sense, but without following the syntax (structure) mandated by your compiler, you’ll never be able to have functioning code.
What is Natural Language Processing
Natural Language Processing is a branch of computer science that allows computers to ingest, compare and derive meaning from human languages. Natural language leans on the fields of linguistics and computer science to make models from text and speech.

Where Do We Get Data For Natural Language Processing
One of the best ways to achieve human-like NLP (natural language processing) models is by using text data from social media. This is because humans type more casually and naturally on social media platforms. Models like GPT-3 have leveraged Wikipedia and other sources also.
How is Semantic Similarity Measured In A Sentence?
Semantic similarity is measured in a sentence by the cosine distance between the two embedded vectors. While many think this calculation is complex, creating the word or sentence embeddings is much more complicated than the cosine calculation.
While many (wrongly) believe that euclidean distance and cosine similarity are the same, they’re computing two different things.
It’s easiest to see with an incredible picture I drew in PowerPoint.
Think of each sentence as a vector mapped into some subspace.
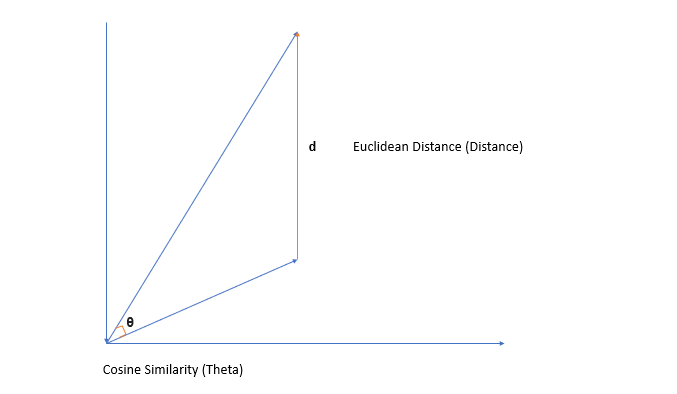
While these vectors’ magnitude (or length) could grow to infinity or take on any values greater than 0, their cosine similarity would not change.
This makes sense; if one sentence uses the word “dog” 15 times, and the other only uses it twice, these sentences are still relevant to the word “dog.”
Cosine similarity also takes advantage of the fact that documents can be of different lengths since the length of the vectors does not matter after normalization.
However, as your length grows, your euclidean distance will change.
This also makes sense; we can’t normalize every vector in things like text classification, as there is significant information gained from knowing if something was mentioned five or three times.
What is Text Similarity?
Text similarity is a component of Natural Language Processing that helps us find similar pieces of text, even if the corpus (sentences) has different words. People can express the same concept in many different ways, and text similarity allows us to find the close relationship between these sentences still.
Think about the following two sentences:
“The train leaves sometime after 12”
“We depart at about 10 after 12”
While these sentences barely even use the exact words, they are semantically very similar, while their lexical similarity is nearly non-existent.
What Are Word Embeddings?
The most important part of Natural Language Processing is the embedding vector. How we calculate our word vectors and sentence vectors is crucial to the accuracy of our models.
Word2vec and Word Embeddings
Word2Vec is a machine learning model that produces word embeddings. Given the word, we can build representation vectors (an array of numbers) that will represent this word.
Lucky for us, Word2vec is pre-trained on google news data.
While you can train your Word2Vec embeddings, you’ll have a better time using the pre-trained ones.
# load a word2vec model in python using gensim, load their spec
import gensim.downloader as api
word2vec = api.load('word2vec-google-news-300')
word2vec['dog']
While we have much more about the downfalls of word2vec in this article, creating embeddings at the word level leaves a simple-to-understand problem.
Take a look at the sentence pairs here:
The zoologist loves studying bats
The baseball player is so upset, he keeps breaking his bats
It only took you 1-2 seconds to realize these sentences aren’t talking about the same thing, and even though bats are the same word, it has two different meanings.
So, creating these vectors from just the individual words is not the answer; what is a way we can improve on the idea of word embedding?
What are Sentence Embeddings?
Sentence embedding is the process of representing a sentence as a vector. Sentence embedding takes many concepts from word embedding and vector representation, but instead of looking at each word isolated, it looks at each word in the context of each sentence.
In the above example, all we looked at was each word isolated on its own to get an embedding space for it.
Will the idea of using the whole sentence allow better information retrieval?
The Downfalls of Term Frequency-Inverse Document Frequency (TF-IDF)
Term Frequency- Inverse Document Frequency (TF-IDF) combines two different topics. This combines term frequency, the number of times the word appears in a document, and the idea behind document frequency, which counts how many documents have that word.
Something that confuses many people is that a TFIDF value for a specific word is specific to a single document d.
While an IDF value (Inverse Document Frequency) is the value for the whole corpus.
While the math gets pretty complicated pretty quickly, TF-IDF typically can answer the question, “How important is this topic from my corpus at d1 compared to d2”.
While this will get us close to Text similarity, it poses some problems.
Using the idea behind TF-IDF, the two sentences
Doc1: The quick brown fox was hungry and jumped over the fence.
Doc2: The quick brown fox, while escaping, jumped over the fence.
If you were to compute the TF-IDF for “fox” for each of these sentences, “fox” is equally relevant for both document 1 and document 2.

While this helps with similarity scores between these two documents (sentences), they’re not discussing the same thing.
In one scenario, the fox was trying to eat and jumped over the fence.
In the other sentence, the fox ran away when it jumped over the fence.
While we are getting close to semantic similarity, we’re not there yet.
Creating Sentence Embeddings with BERT
BERT is a state-of-the-art pre-trained NLP algorithm. BERT (Bidirectional Encoder Representations from Transformers) takes advantage of both the read-left and the read-right context in all model layers. This creates a model that can become highly accurate with only one in-between output layer.
While you could teach a whole class on BERT and its improvements over (literally) everything in the field, it’s much easier just to read their paper.
Downsides of BERT in Sentence Similarity
While BERT achieved state-of-the-art performance on all sentence pair tasks, both sentences must be fed into the network. The computational overhead of this is extreme. Finding the most semantic similar pair of sentences in a 10,000 sentence document would take about 65 hours.

So, we now have the accuracy and the state-of-art model, but we’re missing the speed.
We obviously can’t spend 65 hours on a 10,000-sentence document.
What do we do?
Improvements made by Sentence-BERT
Sentence-BERT (SBERT) takes advantage of the state-of-the-art performance from BERT, with a different architecture. This allows things like cosine similarity to be found much faster. For example, a 65-hour sentence similarity search in BERT would take 5 seconds with SBERT.
While I’m just slightly introducing you to the topic, SBERT is another must-read paper. You can find that paper here.
Now we have the accuracy, the state-of-the-art model, and the speed.
We just need the code!
How Do You Compare The Sentence Similarity Between Two Sentences In Python?
# comparing the two sentences using SBERT and Cosine Similarity
# here's the install command
#!pip install -U sentence-transformers
import pandas as pd
from sentence_transformers import SentenceTransformer, util
# load our Sentence Transformers model pre trained!!
model = SentenceTransformer('all-MiniLM-L6-v2')
# as always, we will get sentences from a
# public kaggle dataset
# https://www.kaggle.com/datasets/columbine/imdb-dataset-sentiment-analysis-in-csv-format?resource=download
df = pd.read_csv('imbd_train_dataset.csv')
# while this data has lots of good info, we just need the reviews
# let's grab 2000
# in real-life, you should not clean data like this
# since this wasn't a data cleaning tutorial I didn't want to bloat
# the code
# this is not production ready data!!
sentences = [sentence.lower()\
.replace('br','')\
.replace('<',"")\ .replace(">","")\
.replace('\\',"")\
.replace('\/',"")\
for sentence in df.text.sample(n=2000)]
#see a sentence, and our length
print(sentences[5:6], f'\n\nLength Of Data {len(sentences)}')

# lets find the semantically closest sentence to a random sentence
# that we come up with, in our dataset
# i like action movies, mission impossible is one of my favorites
our_sentence = 'I really love action movies, huge tom cruise fan!'
# lets embed our sentence
my_embedding = model.encode(our_sentence)
# lets embed the corpus
embeddings = model.encode(sentences)
#Compute cosine similarity between my sentence, and each one in the corpus
cos_sim = util.cos_sim(my_embedding, embeddings)
# lets go through our array and find our best one!
# remember, we want the highest value here (highest cosine similiarity)
winners = []
for arr in cos_sim:
for i, each_val in enumerate(arr):
winners.append([sentences[i],each_val])
# lets get the top 2 sentences
final_winners = sorted(winners, key=lambda x: x[1], reverse=True)
for arr in final_winners[0:2]:
print(f'\nScore : \n\n {arr[1]}')
print(f'\nSentence : \n\n {arr[0]}')

Let me know if you have any idea what these movies are.
They sound like good ones!
