

Topic modeling is a dense but gratifying subject.
Knowing how to put your text into specific topics is crucial to understanding the different genres within your text.
Utilizing topic modeling also allows you to quickly ingest ideas from your text no matter the size of the text in your corpus.
In the beginning, we briefly introduce topic models, then a deep dive into what automatic labeling is and why you need it compared to previous approaches.
At the bottom is complete python code on automatic labeling.

What is Topic Modeling?
Topic Modeling is a genre of techniques used to identify latent themes in a corpus.
In non-machine learning language, it’s strategies used to theme enormous groups of text data together that would be hard (or impossible) to do yourself.
Beginnings of Topic Models
Topic modeling first showed its head as Latent Dirichlet Allocation (LDA) from David Blei. (Paper)
David Bleh was interested in determining if a machine learning algorithm could be trained (using some forms of Bayesian Learning) to detect themes in different scientific abstracts.
A powerful text derivation from the LDA model was the idea of using mixed models on clusters to prevent accuracy loss.
Think about it this way; this research effort allowed the word vectors to belong to multiple categories and not just a single topic.
For example, is a dog a pet or an animal? The answer is probably both.
Mixed Membership Model
You lose a lot of information when you programmatically force different topics into specific categories.
This is where the idea of using the Mixed Membership Model with the corpus began.
Every document will have a little resemblance to each topic, allowing us to think of each document as a mixture of topics.
Topic Modeling Process
LDA model will return the top n words for each topic (k). These top words would now be classified into multiple topic labels with their respective topic distribution.
When your topic model returns the labels, you’ll want to see if the topic labeling answers make sense.
Do the responses for a given topic show any form of resemblance?
You’re probably done if you seem to have a topic distribution that makes a ton of sense.
If there seem to be multiple clusters based on one topic, you probably should reduce k, the number of topics.
If you have some clusters that feel like they’re being forced together, you’ll want to increase k to give the topic model the chance to spread these clusters out.
The Problem With Latent Dirichlet Allocation
We quickly start to see a problem with the Latent Dirichlet Allocation Model, where we pick random K values and almost create the model we’re looking for.
In this scenario, we’re prone to overfitting. Altering our dataset and model until we arrive at the desired outcome.
This leads us to need a way for the model to decide what is the best label candidate for our process.
Why We Need Automatic labeling
If we are allowed constantly edit what topics manually appear, we create a situation where results are not repeatable, and outputs are up to debate.
For example, if your colleague thinks that the words “[pirate, ship, cruise ship]” shouldn’t belong to the same topic, but you do – who is right?
What is BERT
Now that we know that some other techniques are not the answer, we dive deeper into different NLP algorithms.
This leads us to BERT (Bidirectional Encoder Representations from Transformers) (Source)

BERT works by converting the words in sentences to word vectors.
BERT improved on the previous ideas of Word2Vec, where it used a fixed embedding word vector.
The problem with Words2Vec is easy to understand from the words in the sentences below.
Watch out up there and take a left
Becareful out there, we almost got left
While both of these sentences structurally are very similar and sentiment-wise pretty identically, semantically, these sentences are very far apart.
One is about an event (turning left), and the other is about being left behind.
The word “left” in these sentences does not even mean the same thing.
So what do we do?
BERT Can Generate Contextualized embeddings
With contextualized embeddings, the word embeddings for “left” in these sentences will differ.
Since BERT is bidirectional, it reads all the words in a sentence at once and creates sentence vectors along with the individual word vectors.
Let’s see how BERT would categorize some text data.
Other Machine Learning Python Tutorials
We have a lot of additional machine learning python tutorials built just like this one.
This will help you get a more in-depth understanding of machine learning techniques and the different ways you can implement these algorithms in python.
Links to those articles are below:
- K Mode Clustering Python
- Multivariate Polynomial Regression Python
- K-Means Accuracy Python with Silhouette Method
- How Do You Do A Chi-Square Test In Pandas
- Semantic Similarity Between Sentences (python)
Python Code for Labeling Topic Models Using BERT
#Automatic Labeling in Python
# installs
#!pip install bertopic[visualization]
#!pip install numpy
#!pip install pandas
# import what we need the for the analysis
import numpy as np
import pandas as pd
from copy import deepcopy
from bertopic import BERTopic
import random
# we will need some data for this, i'm using pg10 from here
#https://www.kaggle.com/datasets/tentotheminus9/religious-and-philosophical-texts?resource=download
data = pd.read_csv('pg10.txt', delimiter='\t')
print(data.sample(n=15))

# we can clean these up a bit
# convert our dataframe into an array of text
corpus = data.iloc[:,0].values
# some light cleaning on the text for better outputs
final_corpus = []
# for each line in the corpus
for val in corpus:
# if the line is longer than 10 characters
if len(val) > 10:
# lets rebuild it with clean text
cleaning_array = ''
# for each character in that line of text
for character in val:
# if its alnum or a space
if character.isalpha() or character == ' ':
# rebuild the sentence in lowercase
cleaning_array += character.lower()
# add it to our final corpus
final_corpus.append(cleaning_array)
# 71533 lines to put into topics
print(final_corpus[25:40], len(final_corpus))

# initialize our BERTopic Model (instance of class)
model = BERTopic(language='english')
# lets extract the most different topics from a random 6000 line sample
#randomize the list
random.shuffle(final_corpus)
all_topics, all_probs = model.fit_transform(final_corpus[2000:8000])
# lets see the top frequencies 97 total
model.get_topic_freq()

# we see our -1 topic, where many words are stuffed (stop words)
model.get_topic(-1)
# see the contents of topic 8 etc..
model.get_topic(8)
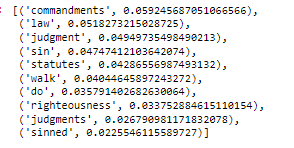
# visual of our topics
model.visualize_topics()
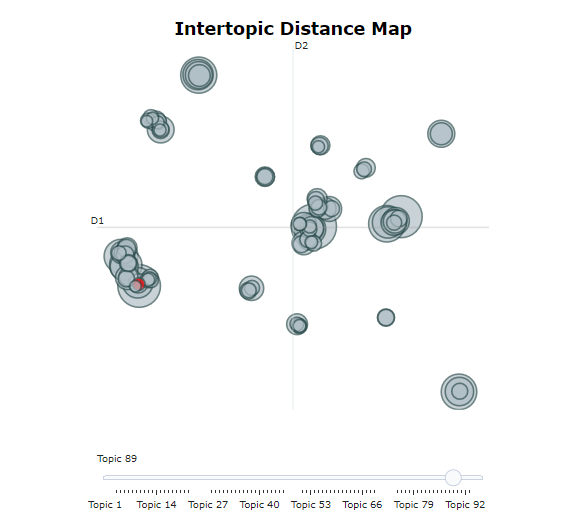
Now all of our text is grouped into a category, spatially laid out to understand how these terms interact in some subspace.
