

Keras, while powerful, does have many different hyperparameters to choose from.
Messing up steps_per_epoch while modeling with the .fit method in Keras can create a ton of problems.
This guide will show you what steps_per_epoch does, how to figure out the correct number of steps, and what happens if you choose steps_per_epoch wrong.
Steps Per Epoch Keras
The best way to set steps per epoch in Keras is by monitoring your computer memory and validation scores. If your computer runs out of memory during training, increase the steps_per_epoch parameter. If your training score is high, but your validation score is low, you’ll want to decrease steps_per_epoch as you are overfitting.
How does the number of steps affect batch size?
Remember, in machine learning, an epoch is one forward pass and backward pass of all the available training data.
If you have a dataset with 2500 lines, once all 2500 lines have been through your neural network’s forward and backward pass, this will count as an epoch.
Batch size in Keras
Continuing with our previous example, we still have 2500 lines in our dataset.
However, what happens if your computer cannot load 2500 lines into memory to train on?
This data needs to be split up.
We will need to split up our dataset into smaller chunks; that way, we can process our input.
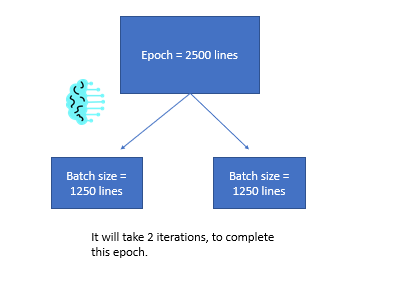
This would work for us since our computer could handle the 1250 lines and using a higher number of batches than one will allow us to alter the weights twice instead of once.
Understanding features during modeling is important. We wrote Keras Feature Importance to give a good intro so you could understand your models better.
Downside of setting the batch size in Keras
The above process worked great, but what if we don’t always know the size of our training data?
For example, if one epoch is 3000 lines, the next epoch is 3103 lines, and the third epoch is 3050 lines.
These extra 100 lines probably wouldn’t matter much for our model or computer memory, but how would you know what to set the batch_size to?
You could write a function or try some default argument to test if you could figure it out, but it would probably be a waste of development time.
Using steps_per_epoch with training data
Let’s continue with our example above, where we had one epoch is 3000 lines, the next epoch is 3103 lines, and the third epoch is 3050 lines.
We have a general idea of the max capacity our training data can be in each batch size, but it would be hard to know if it should be 1500 or 1525.
This is where steps_per_epoch comes in.
Instead of our picture above, what if we just set steps_per_epoch = 2?
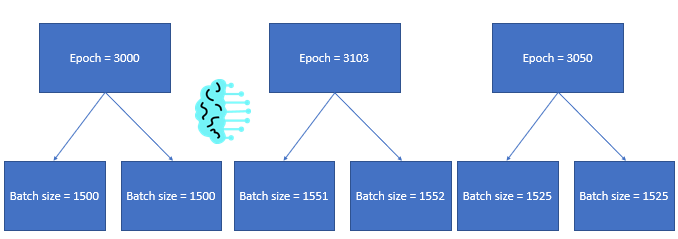
Setting steps_per_epoch within your model allows you to handle any situation where the number of samples in your epoch is different.
We can see that the number of batches has not changed, and even though the batch size has gone up and down, we will still have the same batch size per epoch.
Validation Steps
Now that we’ve reviewed steps per epoch, how does this affect our model outcomes?
During training, you’ll want to make sure that method is correct, and one way to test this while you train your model is by using validation data.
Continuing with our example above, we know we want to increase the iterations of each epoch, as it allows us to increase the amount of time that we update the weights in our neural network.
Many newcomers will then ask why don’t we just set steps per epoch equal to the amount of data in our epoch?
This is a great thought, but doing this while training will result in some horrible accuracy problems.
Validation data
Continuing on the thought above, why can’t we just set the batch size = 1, or steps per epoch equal to the amount of data in the epoch?
Doing this will result in a flawed model, as this model is trained incorrectly and will be overfitting the training data. (Read More)
So, we know we need multiple batches, but we can’t set the number of batches equal to the amount of data.
How do we know how big our batch size is supposed to be?
This is where we use our validation data.
Finding the correct steps per epoch
Modeling in machine learning is an iterative process, and very rarely will you get it right on the first try.
One of the keys to modeling correctly is the different layers. Dense Layer is fundamental in machine learning and is something you should probably check out.
It doesn’t matter how long you’ve been at this or how much knowledge you have on the topic; machine learning is (literally) about trial and error.
The best way to find the steps_per_epoch hyperparameter is by testing.
I like to start with a value at around ten and go up or down based on the size of my training data and the accuracy of my validation dataset.
For example, if you start modeling and quickly run out of memory, you need to increase your steps per epoch. This will lower the amount of data being pushed into memory and will (theoretically) allow you to continue modeling.
Starting your model correctly is how you have success during modeling, we will teach you how in Keras Input Shape.
But remember, as we increase this number, we be susceptible to overfitting the training data.
How to know when you’re overfitting on training data in Keras
In Keras, there is another parameter called validation_split.
Some others, like Keras Shuffle, are also super important for modeling accuracy.
This value is a decimal value that will tell your Keras model how much of the data to leave out to test against.
Your model will have never seen this data before, and after each epoch, Keras will test your trained model against this validation data.
Let’s say that we set validation_split = .2; this will hold out 20% of the data from our training.
While modeling, we expect our training accuracy and validation accuracy to be pretty close. (Understanding accuracy)
What happens when our training accuracy is much higher than our scores on the validation data?
This sadly means we have overfit on our data and need to make changes in the model to combat this.
To make things clear, I do want to say that there are many reasons why you can overfit a model, and steps_per_epoch is just one of them.
But one of the first things that I do if I am overfitting during modeling is reduce the number of steps_per_epoch that I previously set.
This will increase the amount of data in each iteration, hopefully keeping the model from overlearning some of the noise in our data.
