

In some machine learning problems, it’s not uncommon to have thousands of variables. While this is nice, keeping that many variables in your dataset will lead to many problems down the road.
But don’t worry, we’ll teach you how to fix that.
In this article, you’ll learn:
- Why Feature Selection Is Important
- Using SelectKBest For Feature Selection
- Python Code For Regression Problems
- Python Code For Classification Problems
- SelectKBest Alternatives For Feature Selection
Why Feature Selection is Important in Data Science
In data science, you need to perform a feature selection method before moving on to modeling your data.
There are a couple of reasons why this is so important:
It can lead to overall higher-quality models.
By selecting only the most relevant features, you can reduce noise and improve the accuracy of your model.
Second, feature selection can speed up training time. Removing features that are not useful for the prediction can train your model faster.

Feature selection can reduce storage requirements.
If you have a large dataset with many features, selecting only the most important features can save space, especially in tree methods that are known to become very large.

Feature selection can improve interpretability.
By removing features that are not needed to make predictions, you can make your model simpler and easier to understand for stakeholders with questions.
Feature selection can lead to nicer and more compact visualizations.
Selecting only the most important features allows you to create more helpful and visually appealing visualizations, as visualization space isn’t wasted on features with no predictability.
How to Do Feature Selection with SelectKBest On Your Data (Python With Scikit-Learn)
Below, in our two examples, we’ll show you how to select features using SelectKBest in scikit-learn.
This function will give you a score to help you keep only the most important features in your dataset.
Using SelectKBest With Regression Example To Select Best Features
# imports
import pandas as pd
import numpy as np
# as always, public dataset
# https://www.kaggle.com/datasets/hellbuoy/car-price-prediction
df = pd.read_csv('car-price.csv')
# for this problem, lets only focus on numerical columns
df = df[['wheelbase',
'enginesize','boreratio','stroke',
'horsepower','peakrpm','citympg',
'highwaympg','price']]
X = df[[col for col in df.columns if col != 'price']]
y = df['price']
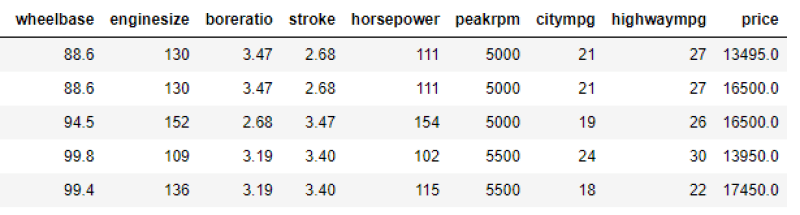
df.head()Below is our full dataframe
from sklearn.feature_selection import SelectKBest
# for regression, we use these two
from sklearn.feature_selection import mutual_info_regression, f_regression
# this function will take in X, y variables
# with criteria, and return a dataframe
# with most important columns
# based on that criteria
def featureSelect_dataframe(X, y, criteria, k):
# initialize our function/method
reg = SelectKBest(criteria, k=k).fit(X,y)
# transform after creating the reg (so we can use getsupport)
X_transformed = reg.transform(X)
# filter down X based on kept columns
X = X[[val for i,val in enumerate(X.columns) if reg.get_support()[i]]]
# return that dataframe
return X
New_X = featureSelect_dataframe(X, y, mutual_info_regression, 7)
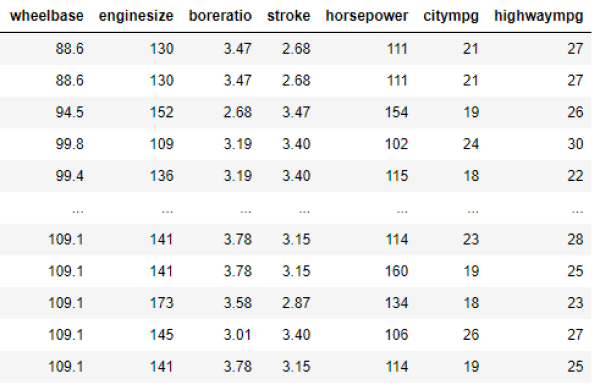
New_XWe see that mutual_info_regression only kept these 7 columns
# took peakrpm over stroke
New_X = featureSelect_dataframe(X, y, f_regression, 7)
New_XCompared to f_regression that only kept these 7 columns

Using SelectKBest With Classification Example To Select Best Features
# imports
import pandas as pd
import numpy as np
# as always, public dataset
# https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009
df = pd.read_csv('winequality-red.csv')
# filter out our quality variable from the rest
X = df[[val for val in df.columns if val != 'quality']]
y = df['quality']
df.head()Below is our dataframe

from sklearn.feature_selection import SelectKBest
# for classification, we use these three
from sklearn.feature_selection import chi2, f_classif, mutual_info_classif
# this function will take in X, y variables
# with criteria, and return a dataframe
# with most important columns
# based on that criteria
def featureSelect_dataframe(X, y, criteria, k):
# initialize our function/method
reg = SelectKBest(criteria, k=k).fit(X,y)
# transform after creating the reg (so we can use getsupport)
X_transformed = reg.transform(X)
# filter down X based on kept columns
X = X[[val for i,val in enumerate(X.columns) if reg.get_support()[i]]]
# return that dataframe
return X
New_X = featureSelect_dataframe(X, y, chi2, 7)
New_XWe see that chi2 only kept these 7 columns
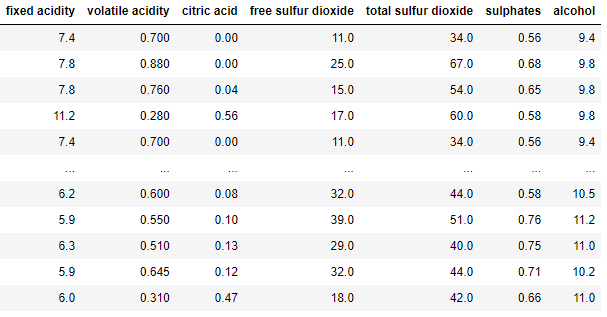
New_X = featureSelect_dataframe(X, y, f_classif, 7)
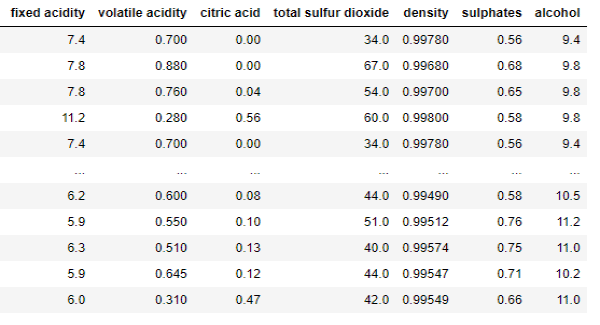
New_XWe see that f_classif only kept these 7 columns

New_X = featureSelect_dataframe(X, y, mutual_info_classif, 7)
New_XWe see that mutual_info_classif only kept these 7 columns
SelectKBest Alternatives for Feature Selection
There are a few alternatives to SelectKBest for feature selection; some of these live outside of the scikit-learn package:
The three main pillars of Feature Selection are:
- Filter Methods
- Ranking features, where the highest ranked features are kept based on some ranking factor (like chi2) and applied to your target variable
- Wrapper Methods
- Wrapper Methods work by using the predictor performance as the objective function and using search algorithms to find a subset that maximizes performance.
- Embedded Methods
- Before splitting any data, embedded methods use variable selection as part of the training process.
Read more on these here, in this paper (Source).
Other Articles In Our Machine Learning 101 Series
We have many quick guides that go over some of the fundamental parts of machine learning. Some of those guides include:
- Welch’s T-Test: Do you know the difference between the student’s t-test and welch’s t-test? Don’t worry, we explain it in-depth here.
- Parameter Versus Variable: Commonly misunderstood – these two aren’t the same thing. This article will break down the difference.
- Reverse Standardization: Another staple in our 101 series is an introductory article teaching you about scaling and standardization.
- Criterion Vs. Predictor: One of the first steps in statistical testing is the independent and dependent variables.
- CountVectorizer vs. TfidfVectorizer: Interested in learning NLP? This is a great guide to jump into after learning about two famous distributions.
- Gini Index vs. Entropy: Learn how decision trees make splitting decisions. These two are the workhouse of top-performing tree-based methods.
- Heatmaps In Python: Visualizing data is key in data science; this post will teach eight different libraries to plot heatmaps.
- Normal Distribution Vs. Uniform Distribution: Two key distributions will pop up everywhere in data science.
